如何减少检索延迟
¥How to reduce retrieval latency
本指南假设你熟悉以下概念:
¥This guide assumes familiarity with the following concepts:
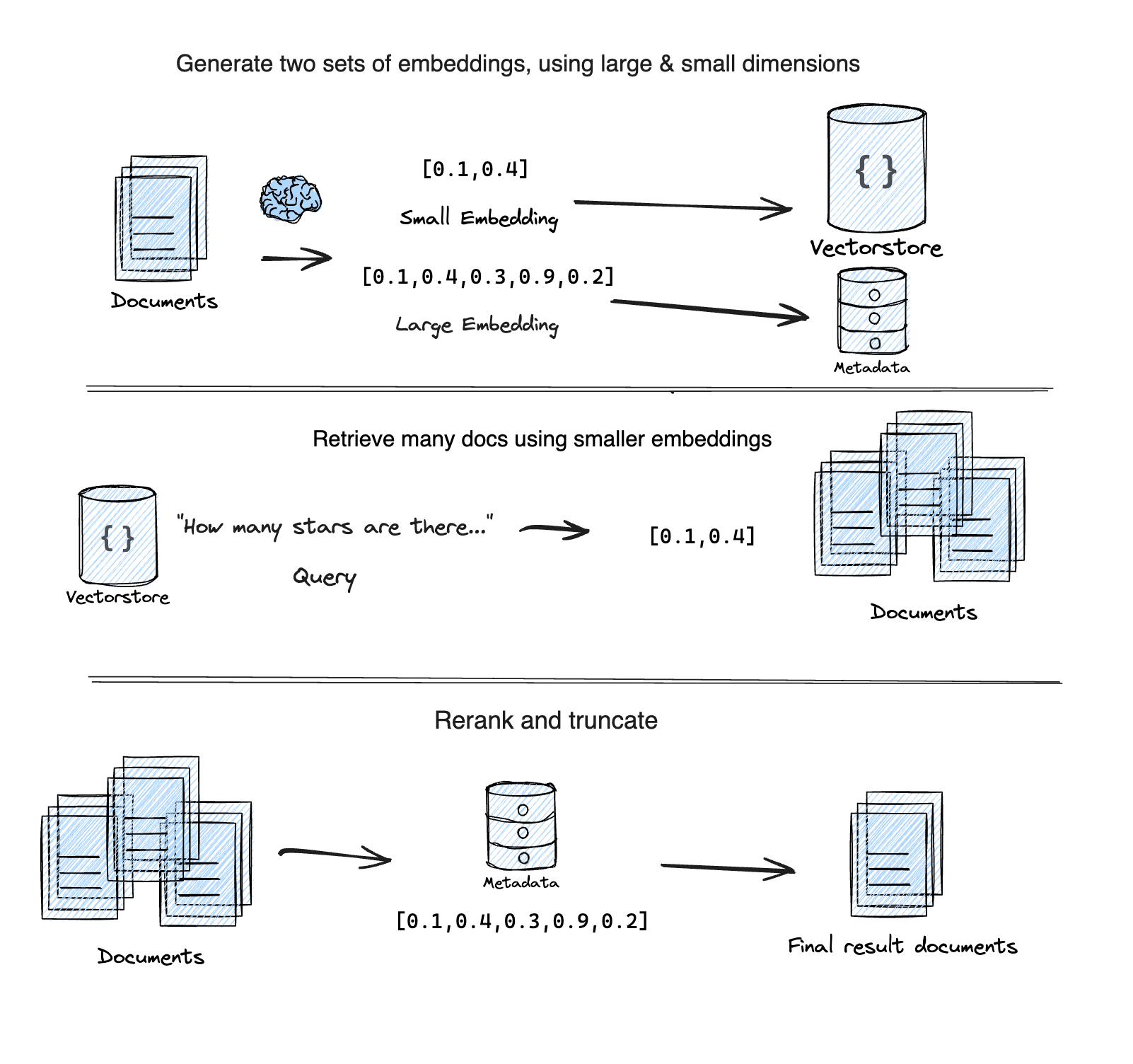
减少检索延迟的一种方法是通过一种称为 "自适应检索" 的技术。MatryoshkaRetriever 使用 Matryoshka 表征学习 (MRL) 技术,通过两个步骤检索给定查询的文档:
¥One way to reduce retrieval latency is through a technique called "Adaptive Retrieval".
The MatryoshkaRetriever uses the
Matryoshka Representation Learning (MRL) technique to retrieve documents for a given query in two steps:
首次测试:使用 MRL 嵌入中的低维子向量进行初始、快速但精度较低的搜索。
¥First-pass: Uses a lower dimensional sub-vector from the MRL embedding for an initial, fast, but less accurate search.
第二遍:使用完整的高维嵌入对第一次传递的排名靠前的结果进行重新排序,以提高准确率。
¥Second-pass: Re-ranks the top results from the first pass using the full, high-dimensional embedding for higher accuracy.
它基于这篇 Supabase 博客文章 “Matryoshka 嵌入”:使用自适应检索实现更快的 OpenAI 向量搜索。
¥It is based on this Supabase blog post "Matryoshka embeddings: faster OpenAI vector search using Adaptive Retrieval".
设置
¥Setup
- npm
- Yarn
- pnpm
npm install @langchain/openai @langchain/community @langchain/core
yarn add @langchain/openai @langchain/community @langchain/core
pnpm add @langchain/openai @langchain/community @langchain/core
要遵循以下示例,你需要一个 OpenAI API 密钥:
¥To follow the example below, you need an OpenAI API key:
export OPENAI_API_KEY=your-api-key
我们还将使用 chroma 作为向量存储。按照 此处 的步骤进行设置。
¥We'll also be using chroma for our vector store. Follow the instructions here to setup.
import { MatryoshkaRetriever } from "langchain/retrievers/matryoshka_retriever";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { faker } from "@faker-js/faker";
const smallEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-small",
dimensions: 512, // Min number for small
});
const largeEmbeddings = new OpenAIEmbeddings({
model: "text-embedding-3-large",
dimensions: 3072, // Max number for large
});
const vectorStore = new Chroma(smallEmbeddings, {
numDimensions: 512,
});
const retriever = new MatryoshkaRetriever({
vectorStore,
largeEmbeddingModel: largeEmbeddings,
largeK: 5,
});
const irrelevantDocs = Array.from({ length: 250 }).map(
() =>
new Document({
pageContent: faker.lorem.word(7), // Similar length to the relevant docs
})
);
const relevantDocs = [
new Document({
pageContent: "LangChain is an open source github repo",
}),
new Document({
pageContent: "There are JS and PY versions of the LangChain github repos",
}),
new Document({
pageContent: "LangGraph is a new open source library by the LangChain team",
}),
new Document({
pageContent: "LangChain announced GA of LangSmith last week!",
}),
new Document({
pageContent: "I heart LangChain",
}),
];
const allDocs = [...irrelevantDocs, ...relevantDocs];
/**
* IMPORTANT:
* The `addDocuments` method on `MatryoshkaRetriever` will
* generate the small AND large embeddings for all documents.
*/
await retriever.addDocuments(allDocs);
const query = "What is LangChain?";
const results = await retriever.invoke(query);
console.log(results.map(({ pageContent }) => pageContent).join("\n"));
/**
I heart LangChain
LangGraph is a new open source library by the LangChain team
LangChain is an open source github repo
LangChain announced GA of LangSmith last week!
There are JS and PY versions of the LangChain github repos
*/
API Reference:
- MatryoshkaRetriever from
langchain/retrievers/matryoshka_retriever - Chroma from
@langchain/community/vectorstores/chroma - OpenAIEmbeddings from
@langchain/openai - Document from
@langchain/core/documents
由于某些向量存储的限制,大型嵌入元数据字段在存储之前会被字符串化(JSON.stringify)。这意味着从向量存储中检索元数据字段时,需要对其进行解析 (JSON.parse)。
¥Due to the constraints of some vector stores, the large embedding metadata field is stringified (JSON.stringify) before being stored. This means that the metadata field will need to be parsed (JSON.parse) when retrieved from the vector store.
后续步骤
¥Next steps
现在你已经学习了一种可以帮助加快检索查询速度的技术。
¥You've now learned a technique that can help speed up your retrieval queries.
接下来,查看 关于 RAG 的更广泛教程 或本节以了解如何执行 基于任何数据源创建你自己的自定义检索器。
¥Next, check out the broader tutorial on RAG, or this section to learn how to create your own custom retriever over any data source.