分词器
¥Tokens
现代大型语言模型 (LLM) 通常基于一种 Transformer 架构,该架构处理一系列称为 token 的单元。标记是模型用来分解输入并生成输出的基本元素。在本节中,我们将讨论什么是令牌以及语言模型如何使用它们。
¥Modern large language models (LLMs) are typically based on a transformer architecture that processes a sequence of units known as tokens. Tokens are the fundamental elements that models use to break down input and generate output. In this section, we'll discuss what tokens are and how they are used by language models.
什么是令牌?
¥What is a token?
令牌是语言模型读取、处理和生成的基本单位。这些单元可能因模型提供商的定义方式而异,但通常它们可以表示:
¥A token is the basic unit that a language model reads, processes, and generates. These units can vary based on how the model provider defines them, but in general, they could represent:
一个完整的单词(例如 "apple"),
¥A whole word (e.g., "apple"),
单词的一部分(例如 "app"),
¥A part of a word (e.g., "app"),
或者其他语言成分,例如标点符号或空格。
¥Or other linguistic components such as punctuation or spaces.
模型对输入进行标记的方式取决于其标记器算法,该算法将输入转换为标记。同样,模型的输出以 token 流的形式出现,然后被解码回人类可读的文本。
¥The way the model tokenizes the input depends on its tokenizer algorithm, which converts the input into tokens. Similarly, the model’s output comes as a stream of tokens, which is then decoded back into human-readable text.
token 在语言模型中如何工作
¥How tokens work in language models
语言模型使用标记的原因与它们如何理解和预测语言有关。语言模型并非直接处理字符或整个句子,而是专注于标记,这些标记代表有意义的语言单位。以下是该过程的工作原理:
¥The reason language models use tokens is tied to how they understand and predict language. Rather than processing characters or entire sentences directly, language models focus on tokens, which represent meaningful linguistic units. Here's how the process works:
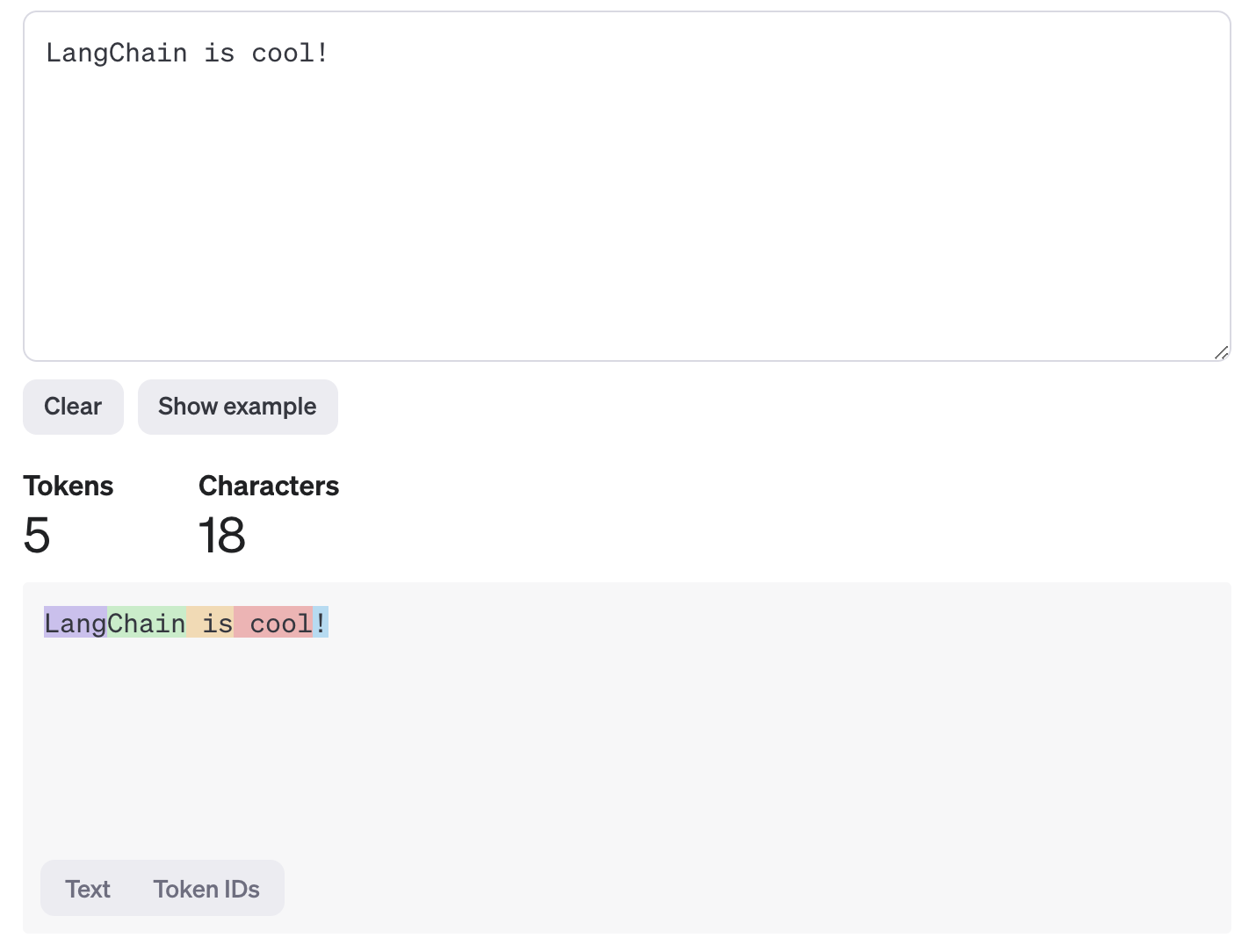
输入标记化:当你为模型提供提示(例如 "LangChain 很棒!")时,分词器算法会将文本拆分为分词器。例如,该句子可以像
["Lang", "Chain", " is", " cool", "!"]一样被标记化。请注意,token 边界并不总是与单词边界对齐。¥Input Tokenization: When you provide a model with a prompt (e.g., "LangChain is cool!"), the tokenizer algorithm splits the text into tokens. For example, the sentence could be tokenized into parts like
["Lang", "Chain", " is", " cool", "!"]. Note that token boundaries don’t always align with word boundaries.
处理:这些模型背后的 Transformer 架构会按顺序处理 token,以预测句子中的下一个 token。它通过分析标记之间的关系、从输入中捕获上下文和含义来实现这一点。
¥Processing: The transformer architecture behind these models processes tokens sequentially to predict the next token in a sentence. It does this by analyzing the relationships between tokens, capturing context and meaning from the input.
输出生成:模型会逐个生成新的 token。这些输出令牌随后会被解码回人类可读的文本。
¥Output Generation: The model generates new tokens one by one. These output tokens are then decoded back into human-readable text.
使用标记代替原始字符可以使模型专注于具有语言意义的单元,从而更有效地捕捉语法、结构和上下文。
¥Using tokens instead of raw characters allows the model to focus on linguistically meaningful units, which helps it capture grammar, structure, and context more effectively.
分词器不必是文本
¥Tokens don’t have to be text
虽然 token 最常用于表示文本,但它们不必局限于文本数据。标记还可以作为多模态数据的抽象表示,例如:
¥Although tokens are most commonly used to represent text, they don’t have to be limited to textual data. Tokens can also serve as abstract representations of multi-modal data, such as:
图片,
¥Images,
音频,
¥Audio,
视频,
¥Video,
其他类型的数据。
¥And other types of data.
在撰写本文时,几乎没有模型支持多模态输出,只有少数模型可以处理多模态输入(例如,文本与图片或音频的组合)。然而,随着人工智能的不断进步,我们预计多模态数据将变得更加普遍。这将允许模型处理和生成更广泛的媒体,显著扩展 token 可以表示的范围以及模型与各种类型数据交互的方式。
¥At the time of writing, virtually no models support multi-modal output, and only a few models can handle multi-modal inputs (e.g., text combined with images or audio). However, as advancements in AI continue, we expect multi-modality to become much more common. This would allow models to process and generate a broader range of media, significantly expanding the scope of what tokens can represent and how models can interact with diverse types of data.
原则上,任何可以表示为 token 序列的事物都可以用类似的方式建模。例如,由一系列核苷酸(A、T、C、G)组成的 DNA 序列可以被标记化并建模,以捕获模式、进行预测或生成序列。这种灵活性使基于 Transformer 的模型能够处理不同类型的序列数据,从而进一步拓宽其在各个字段的潜在应用,包括生物信息学、信号处理以及其他涉及结构化或非结构化序列的字段。
¥In principle, anything that can be represented as a sequence of tokens could be modeled in a similar way. For example, DNA sequences—which are composed of a series of nucleotides (A, T, C, G)—can be tokenized and modeled to capture patterns, make predictions, or generate sequences. This flexibility allows transformer-based models to handle diverse types of sequential data, further broadening their potential applications across various domains, including bioinformatics, signal processing, and other fields that involve structured or unstructured sequences.
有关多模态输入和输出的更多信息,请参阅 multimodality 部分。
¥Please see the multimodality section for more information on multi-modal inputs and outputs.
为什么不使用字符?
¥Why not use characters?
使用标记代替单个字符可以使模型更高效,并且能够更好地理解上下文和语法。标记表示有意义的单位,例如整个单词或单词的一部分,这使得模型能够比处理原始字符更有效地捕捉语言结构。标记级处理还可以减少模型需要处理的单元数量,从而加快计算速度。
¥Using tokens instead of individual characters makes models both more efficient and better at understanding context and grammar. Tokens represent meaningful units, like whole words or parts of words, allowing models to capture language structure more effectively than by processing raw characters. Token-level processing also reduces the number of units the model has to handle, leading to faster computation.
相比之下,字符级处理需要处理更大的输入序列,这使得模型更难学习关系和上下文。标记使模型能够专注于语言含义,从而更准确、更高效地生成响应。
¥In contrast, character-level processing would require handling a much larger sequence of input, making it harder for the model to learn relationships and context. Tokens enable models to focus on linguistic meaning, making them more accurate and efficient in generating responses.
token 如何与文本对应
¥How tokens correspond to text
请参阅 OpenAI 的这篇帖子,了解更多关于如何计算令牌以及如何将其与文本对应的详细信息。
¥Please see this post from OpenAI for more details on how tokens are counted and how they correspond to text.
根据 OpenAI 的帖子,英文文本的大致 token 数量如下:
¥According to the OpenAI post, the approximate token counts for English text are as follows:
1 个 token ~= 4 个英文字符
¥1 token ~= 4 chars in English
1 个 token ~= ¾ 个单词
¥1 token ~= ¾ words
100 个 token ~= 75 个单词
¥100 tokens ~= 75 words