嵌入模型
¥Embedding models
本概念概述重点介绍基于文本的嵌入模型。
¥This conceptual overview focuses on text-based embedding models.
嵌入模型也可以是 multimodal,尽管 LangChain 目前不支持此类模型。
¥Embedding models can also be multimodal though such models are not currently supported by LangChain.
想象一下,你能够捕捉任何文本的精髓。 - 一条推文、文档或书籍 - 以单一、紧凑的形式呈现。这就是嵌入模型的强大之处,它是许多检索系统的核心。嵌入模型将人类语言转换为机器可以理解并快速准确地进行比较的格式。这些模型以文本作为输入,并生成一个固定长度的数字数组,即文本语义的数字指纹。嵌入使搜索系统能够不仅基于关键字匹配,还基于语义理解来查找相关文档。
¥Imagine being able to capture the essence of any text - a tweet, document, or book - in a single, compact representation. This is the power of embedding models, which lie at the heart of many retrieval systems. Embedding models transform human language into a format that machines can understand and compare with speed and accuracy. These models take text as input and produce a fixed-length array of numbers, a numerical fingerprint of the text's semantic meaning. Embeddings allow search system to find relevant documents not just based on keyword matches, but on semantic understanding.
关键概念
¥Key concepts
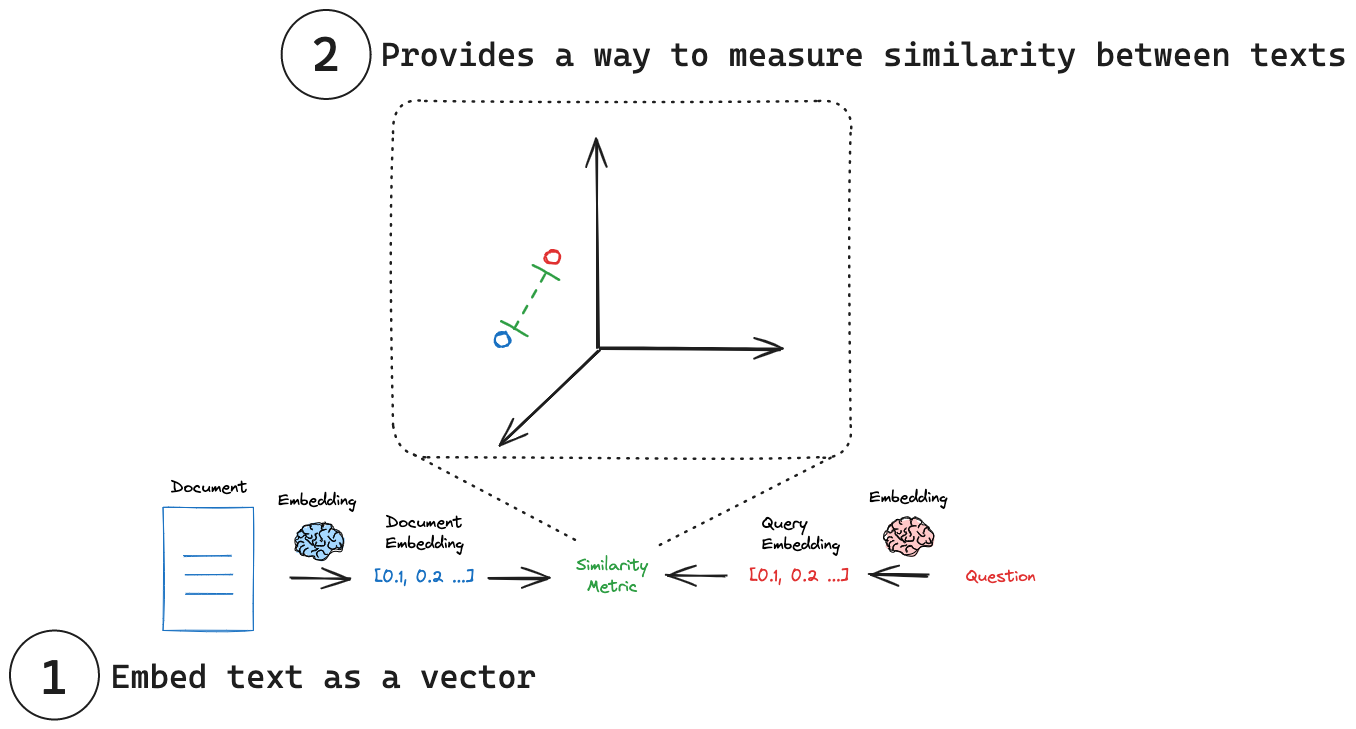
(1)将文本嵌入向量:嵌入将文本转换为数值向量表示。
¥(1) Embed text as a vector: Embeddings transform text into a numerical vector representation.
(2)相似度测量:可以使用简单的数学运算来比较嵌入向量。
¥(2) Measure similarity: Embedding vectors can be comparing using simple mathematical operations.
嵌入
¥Embedding
历史背景
¥Historical context
多年来,嵌入模型的格局发生了显著变化。2018 年,谷歌推出 BERT(来自 Transformer 的双向编码器表示),这是一个关键时刻。BERT 应用 Transformer 模型将文本嵌入为简单的向量表示,从而在各种 NLP 任务中实现了前所未有的性能。然而,BERT 并未针对高效生成句子嵌入进行优化。这一限制促使 SBERT (句子-BERT) 的创建,它调整了 BERT 架构以生成语义丰富的句子嵌入,这些嵌入可以通过余弦相似度等相似度指标轻松进行比较,从而显著降低了查找相似句子等任务的计算开销。如今,嵌入模型生态系统多种多样,众多提供商提供各自的实现。为了应对这种多样性,研究人员和从业人员经常使用诸如海量文本嵌入基准 (MTEB) 此处 之类的基准进行客观比较。
¥The landscape of embedding models has evolved significantly over the years. A pivotal moment came in 2018 when Google introduced BERT (Bidirectional Encoder Representations from Transformers). BERT applied transformer models to embed text as a simple vector representation, which lead to unprecedented performance across various NLP tasks. However, BERT wasn't optimized for generating sentence embeddings efficiently. This limitation spurred the creation of SBERT (Sentence-BERT), which adapted the BERT architecture to generate semantically rich sentence embeddings, easily comparable via similarity metrics like cosine similarity, dramatically reduced the computational overhead for tasks like finding similar sentences. Today, the embedding model ecosystem is diverse, with numerous providers offering their own implementations. To navigate this variety, researchers and practitioners often turn to benchmarks like the Massive Text Embedding Benchmark (MTEB) here for objective comparisons.
请参阅 BERT 经典论文。
¥See the seminal BERT paper.
请参阅 Cameron Wolfe 的 优秀的评论 文章,其中介绍了嵌入模型。
¥See Cameron Wolfe's excellent review of embedding models.
查看 海量文本嵌入基准 (MTEB) 排行榜,全面了解嵌入模型。
¥See the Massive Text Embedding Benchmark (MTEB) leaderboard for a comprehensive overview of embedding models.
接口
¥Interface
LangChain 提供了一个通用接口,用于与它们交互,并为常用操作提供了标准方法。此通用接口通过两种主要方法简化了与各种嵌入提供程序的交互:
¥LangChain provides a universal interface for working with them, providing standard methods for common operations. This common interface simplifies interaction with various embedding providers through two central methods:
embedDocuments:用于嵌入多个文本(文档)¥
embedDocuments: For embedding multiple texts (documents)embedQuery:用于嵌入单个文本(查询)¥
embedQuery: For embedding a single text (query)
这种区别非常重要,因为一些提供程序对文档(待搜索)和查询(搜索输入本身)采用不同的嵌入策略。为了说明这一点,这里有一个使用 LangChain 的 .embedDocuments 方法嵌入字符串列表的实际示例:
¥This distinction is important, as some providers employ different embedding strategies for documents (which are to be searched) versus queries (the search input itself).
To illustrate, here's a practical example using LangChain's .embedDocuments method to embed a list of strings:
import { OpenAIEmbeddings } from "@langchain/openai";
const embeddingsModel = new OpenAIEmbeddings();
const embeddings = await embeddingsModel.embedDocuments([
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!",
]);
console.log(`(${embeddings.length}, ${embeddings[0].length})`);
// (5, 1536)
为方便起见,你还可以使用 embedQuery 方法嵌入单个文本:
¥For convenience, you can also use the embedQuery method to embed a single text:
const queryEmbedding = await embeddingsModel.embedQuery(
"What is the meaning of life?"
);
查看 LangChain 嵌入模型集成 的完整列表。
¥See the full list of LangChain embedding model integrations.
有关如何使用嵌入模型,请参阅这些 操作指南。
¥See these how-to guides for working with embedding models.
集成
¥Integrations
LangChain 提供了许多嵌入模型集成,你可以在 关于嵌入模型 集成页面找到。
¥LangChain offers many embedding model integrations which you can find on the embedding models integrations page.
相似度测量
¥Measure similarity
每个嵌入本质上是一组坐标,通常位于高维空间中。在这个空间中,每个点(嵌入)的位置反映了其对应文本的含义。正如同义词库中相似的词语可能彼此靠近一样,相似的概念最终也会在这个嵌入空间中彼此靠近。这允许直观地比较不同的文本片段。通过将文本简化为这些数值表示,我们可以使用简单的数学运算来快速测量两段文本的相似度,而无需考虑它们的原始长度或结构。一些常见的相似性指标包括:
¥Each embedding is essentially a set of coordinates, often in a high-dimensional space. In this space, the position of each point (embedding) reflects the meaning of its corresponding text. Just as similar words might be close to each other in a thesaurus, similar concepts end up close to each other in this embedding space. This allows for intuitive comparisons between different pieces of text. By reducing text to these numerical representations, we can use simple mathematical operations to quickly measure how alike two pieces of text are, regardless of their original length or structure. Some common similarity metrics include:
余弦相似度:测量两个向量之间夹角的余弦值。
¥Cosine Similarity: Measures the cosine of the angle between two vectors.
欧氏距离:测量两点之间的直线距离。
¥Euclidean Distance: Measures the straight-line distance between two points.
点积:测量一个向量在另一个向量上的投影。
¥Dot Product: Measures the projection of one vector onto another.
相似度度量的选择应根据模型进行选择。例如,OpenAI 建议对其嵌入使用余弦相似度 可以轻松实现:
¥The choice of similarity metric should be chosen based on the model. As an example, OpenAI suggests cosine similarity for their embeddings, which can be easily implemented:
function cosineSimilarity(vec1: number[], vec2: number[]): number {
const dotProduct = vec1.reduce((sum, val, i) => sum + val * vec2[i], 0);
const norm1 = Math.sqrt(vec1.reduce((sum, val) => sum + val * val, 0));
const norm2 = Math.sqrt(vec2.reduce((sum, val) => sum + val * val, 0));
return dotProduct / (norm1 * norm2);
}
const similarity = cosineSimilarity(queryResult, documentResult);
console.log("Cosine Similarity:", similarity);
请参阅 Simon Willison 的 精彩博文和视频 文章,其中介绍了嵌入和相似性度量。
¥See Simon Willison's nice blog post and video on embeddings and similarity metrics.
有关嵌入时需要考虑的相似性指标,请参阅 Google 的 此文档。
¥See this documentation from Google on similarity metrics to consider with embeddings.
请参阅 Pinecone 的 博客文章 文章,了解相似性度量。
¥See Pinecone's blog post on similarity metrics.
请参阅 OpenAI 的 常见问题 文章,了解 OpenAI 嵌入应使用的相似性度量。
¥See OpenAI's FAQ on what similarity metric to use with OpenAI embeddings.