向量存储
¥Vector stores
本概念概述侧重于基于文本的索引和检索,以简化操作。但是,嵌入模型可以是 multi-modal,向量存储可用于存储和检索文本以外的各种数据类型。
¥This conceptual overview focuses on text-based indexing and retrieval for simplicity. However, embedding models can be multi-modal and vector stores can be used to store and retrieve a variety of data types beyond text.
概述
¥Overview
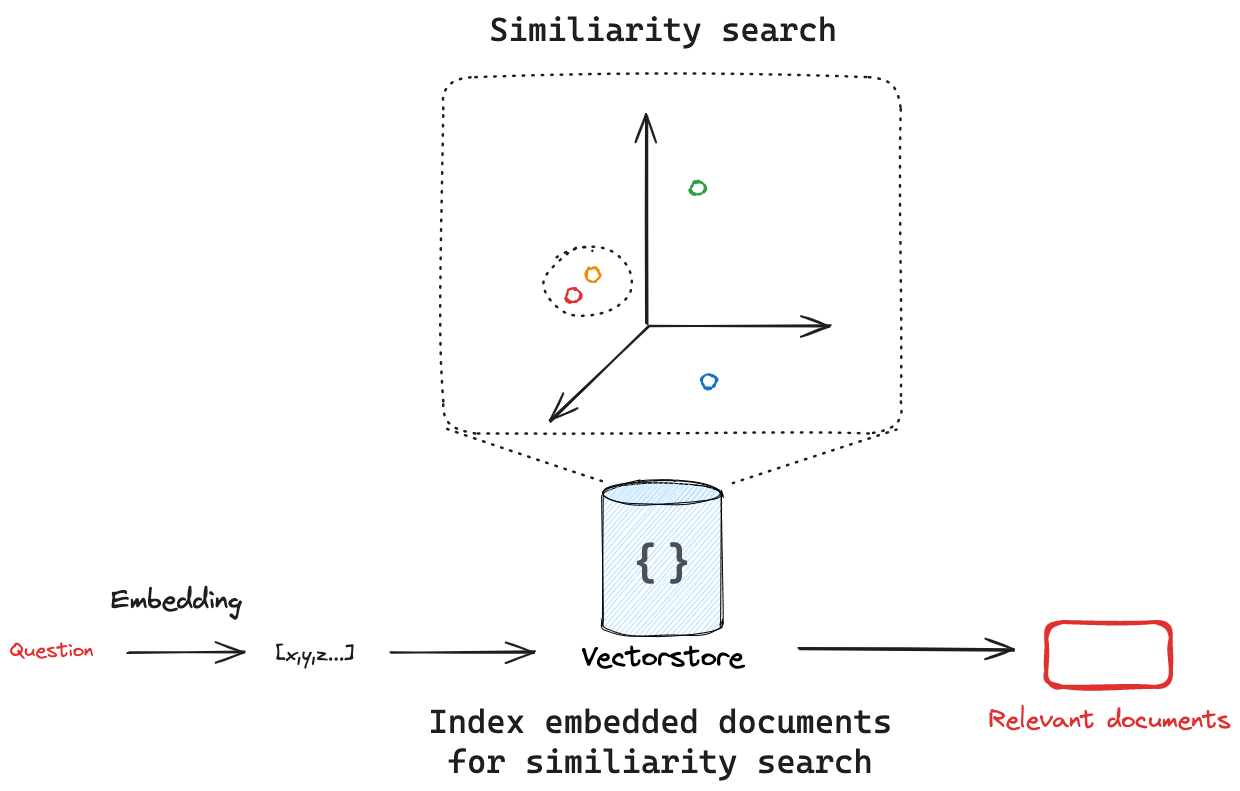
向量存储是一种专门的数据存储,支持基于向量表示的索引和信息检索。
¥Vector stores are specialized data stores that enable indexing and retrieving information based on vector representations.
这些向量被称为 embeddings,用于捕获已嵌入数据的语义。
¥These vectors, called embeddings, capture the semantic meaning of data that has been embedded.
向量存储经常用于搜索非结构化数据(例如文本、图片和音频),以基于语义相似性(而不是精确的关键字匹配)检索相关信息。
¥Vector stores are frequently used to search over unstructured data, such as text, images, and audio, to retrieve relevant information based on semantic similarity rather than exact keyword matches.
集成
¥Integrations
LangChain 集成了大量的 VectorStore,方便用户在不同的 VectorStore 实现之间轻松切换。
¥LangChain has a large number of vectorstore integrations, allowing users to easily switch between different vectorstore implementations.
¥Please see the full list of LangChain vectorstore integrations.
接口
¥Interface
LangChain 提供了一个用于处理向量存储的标准接口,允许用户轻松地在不同的向量存储实现之间切换。
¥LangChain provides a standard interface for working with vector stores, allowing users to easily switch between different vectorstore implementations.
接口包含用于在向量存储中写入、删除和搜索文档的基本方法。
¥The interface consists of basic methods for writing, deleting and searching for documents in the vector store.
关键方法如下:
¥The key methods are:
addDocuments:将文本列表添加到向量存储。¥
addDocuments: Add a list of texts to the vector store.deleteDocuments/delete:从向量存储中删除文档列表。¥
deleteDocuments/delete: Delete a list of documents from the vector store.similaritySearch:搜索与给定查询相似的文档。¥
similaritySearch: Search for similar documents to a given query.
初始化
¥Initialization
LangChain 中的大多数向量在初始化向量存储时都接受嵌入模型作为参数。
¥Most vectors in LangChain accept an embedding model as an argument when initializing the vector store.
我们将使用 LangChain 的 MemoryVectorStore 实现来演示 API。
¥We will use LangChain's MemoryVectorStore implementation to illustrate the API.
import { MemoryVectorStore } from "langchain/vectorstores/memory";
// Initialize with an embedding model
const vectorStore = new MemoryVectorStore(new SomeEmbeddingModel());
添加文档
¥Adding documents
要添加文档,请使用 addDocuments 方法。
¥To add documents, use the addDocuments method.
此 API 可与 文档 对象列表配合使用。Document 对象都具有 pageContent 和 metadata 属性,使其成为存储非结构化文本及其相关元数据的通用方法。
¥This API works with a list of Document objects.
Document objects all have pageContent and metadata attributes, making them a universal way to store unstructured text and associated metadata.
import { Document } from "@langchain/core/documents";
const document1 = new Document(
pageContent: "I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata: { source: "tweet" },
)
const document2 = new Document(
pageContent: "The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata: { source: "news" },
)
const documents = [document1, document2]
await vectorStore.addDocuments(documents)
你通常应该为添加到向量存储的文档提供 ID,这样你就可以更新现有文档,而不必多次添加相同的文档。
¥You should usually provide IDs for the documents you add to the vector store, so that instead of adding the same document multiple times, you can update the existing document.
await vectorStore.addDocuments(documents, { ids: ["doc1", "doc2"] });
删除
¥Delete
要删除文档,请使用 deleteDocuments 方法,该方法接受要删除的文档 ID 列表。
¥To delete documents, use the deleteDocuments method which takes a list of document IDs to delete.
await vectorStore.deleteDocuments(["doc1"]);
或 delete 方法:
¥or the delete method:
await vectorStore.deleteDocuments({ ids: ["doc1"] });
搜索
¥Search
向量存储嵌入并存储添加的文档。如果我们传入一个查询,vectorstore 将嵌入该查询,对嵌入的文档执行相似性搜索,并返回最相似的文档。这抓住了两个重要概念:首先,需要有一种方法来衡量查询与任何 embedded 文档之间的相似度。其次,需要一种算法能够在所有嵌入文档中高效地执行相似性搜索。
¥Vector stores embed and store the documents that added. If we pass in a query, the vectorstore will embed the query, perform a similarity search over the embedded documents, and return the most similar ones. This captures two important concepts: first, there needs to be a way to measure the similarity between the query and any embedded document. Second, there needs to be an algorithm to efficiently perform this similarity search across all embedded documents.
相似度指标
¥Similarity metrics
嵌入向量的一个关键优势在于它们可以使用许多简单的数学运算进行比较:
¥A critical advantage of embeddings vectors is they can be compared using many simple mathematical operations:
余弦相似度:测量两个向量之间夹角的余弦值。
¥Cosine Similarity: Measures the cosine of the angle between two vectors.
欧氏距离:测量两点之间的直线距离。
¥Euclidean Distance: Measures the straight-line distance between two points.
点积:测量一个向量在另一个向量上的投影。
¥Dot Product: Measures the projection of one vector onto another.
有时可以在初始化向量存储时选择相似度度量。请参阅你正在使用的特定向量存储的文档,以了解其支持的相似性指标。
¥The choice of similarity metric can sometimes be selected when initializing the vectorstore. Please refer to the documentation of the specific vectorstore you are using to see what similarity metrics are supported.
有关嵌入时需要考虑的相似性指标,请参阅 Google 的 此文档。
¥See this documentation from Google on similarity metrics to consider with embeddings.
请参阅 Pinecone 的 博客文章 文章,了解相似性度量。
¥See Pinecone's blog post on similarity metrics.
请参阅 OpenAI 的 常见问题 文章,了解 OpenAI 嵌入应使用的相似性度量。
¥See OpenAI's FAQ on what similarity metric to use with OpenAI embeddings.
相似度搜索
¥Similarity search
给定一个相似度指标来衡量嵌入查询与任何嵌入文档之间的距离,我们需要一种算法来有效地搜索所有嵌入文档以找到最相似的文档。有多种方法可以实现这一点。例如,许多向量存储都实现了 HNSW(分层可导航小世界),这是一种基于图的索引结构,可以实现高效的相似性搜索。无论底层使用何种搜索算法,LangChain 向量存储接口都为所有集成提供了一个 similaritySearch 方法。这将接受搜索查询,创建嵌入,查找相似文档,并将它们作为 文档 列表返回。
¥Given a similarity metric to measure the distance between the embedded query and any embedded document, we need an algorithm to efficiently search over all the embedded documents to find the most similar ones.
There are various ways to do this. As an example, many vectorstores implement HNSW (Hierarchical Navigable Small World), a graph-based index structure that allows for efficient similarity search.
Regardless of the search algorithm used under the hood, the LangChain vectorstore interface has a similaritySearch method for all integrations.
This will take the search query, create an embedding, find similar documents, and return them as a list of Documents.
const query = "my query";
const docs = await vectorstore.similaritySearch(query);
许多向量存储支持通过 similaritySearch 方法传递搜索参数。查看你正在使用的特定向量存储的文档,了解其支持的参数。例如,Pinecone 的几个参数是重要的一般概念:许多向量存储支持 k(它控制要返回的文档数量)和 filter(它允许通过元数据过滤文档)。
¥Many vectorstores support search parameters to be passed with the similaritySearch method. See the documentation for the specific vectorstore you are using to see what parameters are supported.
As an example Pinecone several parameters that are important general concepts:
Many vectorstores support the k, which controls the number of Documents to return, and filter, which allows for filtering documents by metadata.
query (string) – Text to look up documents similar to.k (number) – Number of Documents to return. Defaults to 4.filter (Record<string, any> | undefined) – Object of argument(s) to filter on metadata
有关如何使用
similaritySearch方法的更多详细信息,请参阅 操作指南。¥See the how-to guide for more details on how to use the
similaritySearchmethod.有关可传递给特定向量存储的
similaritySearch方法的参数的更多详细信息,请参阅 集成页面。¥See the integrations page for more details on arguments that can be passed in to the
similaritySearchmethod for specific vectorstores.
元数据过滤
¥Metadata filtering
虽然 VectorStore 实现了一种搜索算法,可以有效地搜索所有嵌入文档以找到最相似的文档,但许多 VectorStory 也支持基于元数据的过滤。这允许结构化过滤器减少相似度搜索空间的大小。这两个概念可以很好地协同工作:
¥While vectorstore implement a search algorithm to efficiently search over all the embedded documents to find the most similar ones, many also support filtering on metadata. This allows structured filters to reduce the size of the similarity search space. These two concepts work well together:
语义搜索:直接查询非结构化数据,通常使用嵌入或关键字相似度计算。
¥Semantic search: Query the unstructured data directly, often using via embedding or keyword similarity.
元数据搜索:对元数据应用结构化查询,过滤特定文档。
¥Metadata search: Apply structured query to the metadata, filtering specific documents.
向量存储对元数据过滤的支持通常取决于底层向量存储的实现。
¥Vector store support for metadata filtering is typically dependent on the underlying vector store implementation.
下面是一个使用 Pinecone 的示例,显示我们筛选出所有包含元数据键 source 和值 tweet 的文档。
¥Here is example usage with Pinecone, showing that we filter for all documents that have the metadata key source with value tweet.
await vectorstore.similaritySearch(
"LangChain provides abstractions to make working with LLMs easy",
2,
{
// The arguments of this field are provider specific.
filter: { source: "tweet" },
}
);
请参阅 Pinecone 的 documentation 文章,了解如何使用元数据进行过滤。
¥See Pinecone's documentation on filtering with metadata.
查看支持元数据过滤的 LangChain 向量存储集成列表。
¥See the list of LangChain vectorstore integrations that support metadata filtering.
高级搜索和检索技术
¥Advanced search and retrieval techniques
虽然像 HNSW 这样的算法在许多情况下为高效的相似性搜索提供了基础,但可以采用其他技术来提高搜索质量和多样性。例如,最大边际相关性是一种用于多样化搜索结果的重排序算法,它在初始相似性搜索之后应用,以确保结果更加多样化。
¥While algorithms like HNSW provide the foundation for efficient similarity search in many cases, additional techniques can be employed to improve search quality and diversity. For example, maximal marginal relevance is a re-ranking algorithm used to diversify search results, which is applied after the initial similarity search to ensure a more diverse set of results.
| 名称 | 何时使用 | 说明 |
|---|---|---|
| 最大边际相关性 (MMR) | 当需要使搜索结果多样化时。 | MMR 尝试使搜索结果多样化,以避免返回相似和冗余的文档。 |